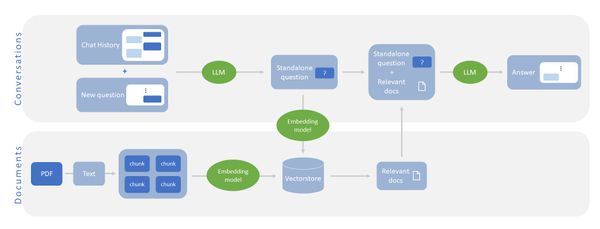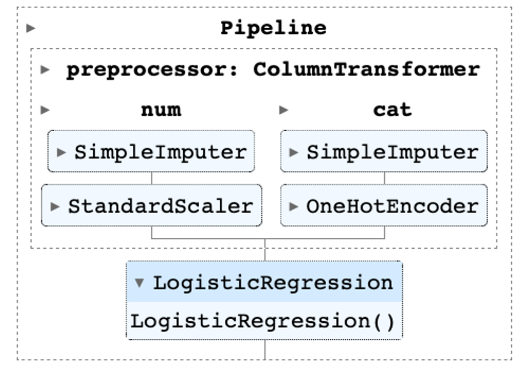
支持向量機(Support Vector Machine, SVM)是機器學習中著名的演算法之一,1992年由Boser et al.提出後,被應用於許多不同領域。
支持向量機與核函數介紹
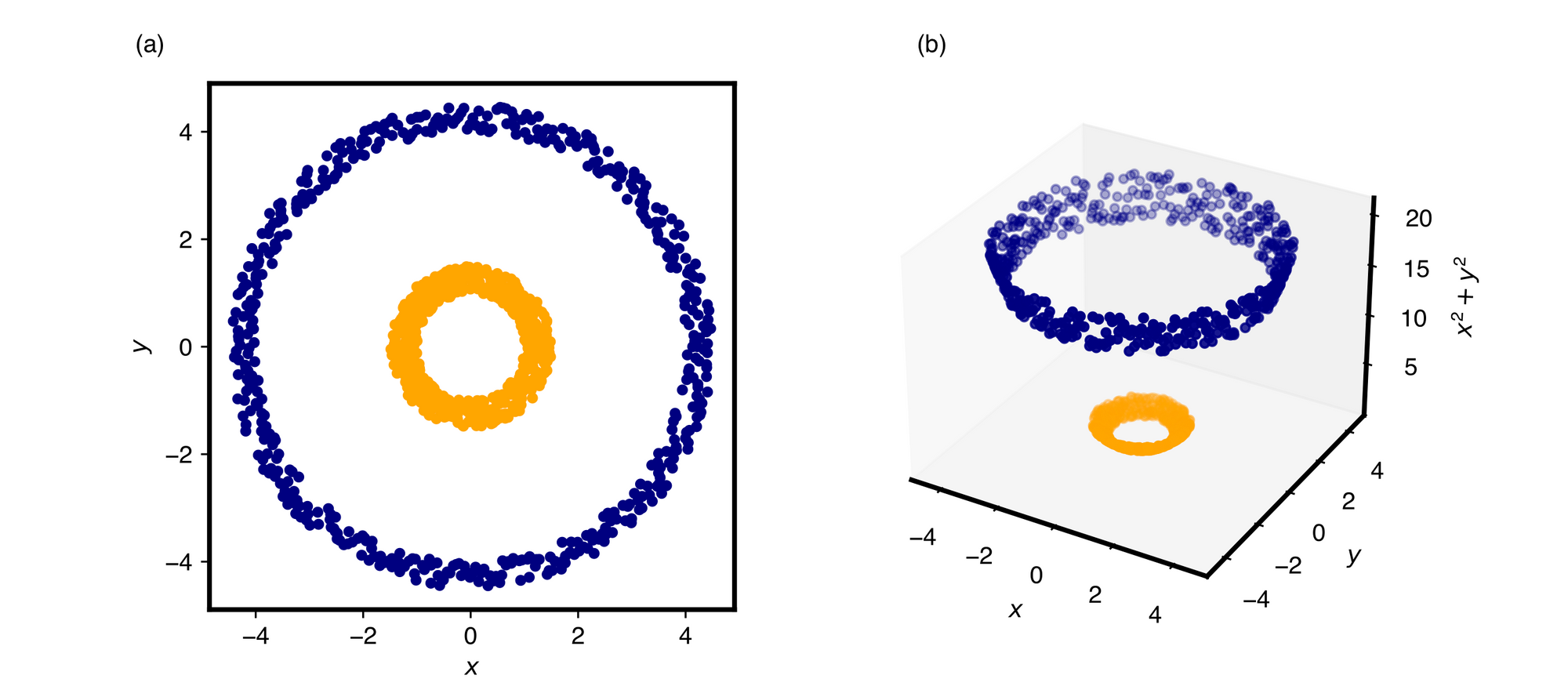
SVM有兩項特色,分別是透過尋找支持向量(Support vector)來最大化分離邊限(Margin of separation),以及核函數(Kernel function)的使用。前者提高模型泛化能力(Generalization ability),後者則將原特徵空間中的資料,經演算法映射到更高維度的特徵空間中,因此原本不可分的資料就有可能藉由非線性映射,在新的特徵空間變得可分隔,如圖1的範例。

(b)是以z=x2+y2進行映射後,資料在新特徵空間的分佈情形。
核函數種類繁多,在論文中以及實務上常使用的有以下兩種:

其中Χi與Χj為兩筆資料,σ與d分別為高斯寬度以及次方數,都是由使用者自訂的超參數,這些超參數直接影響模型學習到的決策邊界。如圖2的範例,當使用高斯核訓練SVM模型,在同樣的C值下,σ值愈小就會使決策邊界變得更為非線性,也更貼近訓練資料,但同時可能導致過擬合(Overfitting),例如可以比較σ = 5與σ = 0.05的結果。
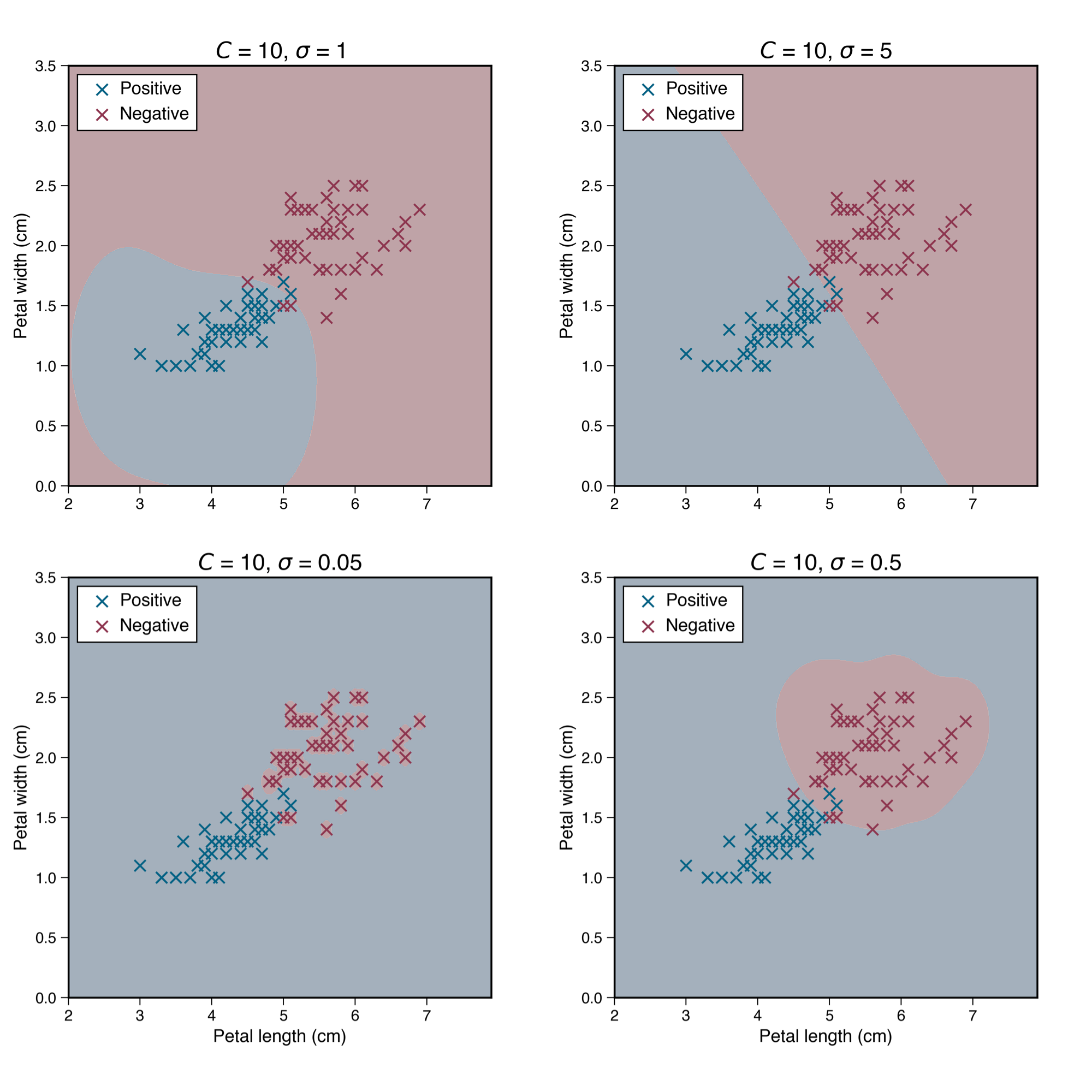
圖2:使用高斯核函數的SVM,在不同的σ值時的決策邊界。資料為Iris Data Set的Petal width、Petal length,正類別為Versicolour,負類別為Virginica,分別對應到圖中的藍色與紅色交叉。底色則顯示該處的決策結果,以較淺的藍、紅色分別表示正、負類別。 一般來說用以上兩者來搭配SVM模型來訓練,效果都不差,而除了上述兩者,也有其他核函數陸續被研究出。本文將介紹的是由Sajad Fathi Hafshejani與Zahra Moberfard於2022年11月所提出的核函數:
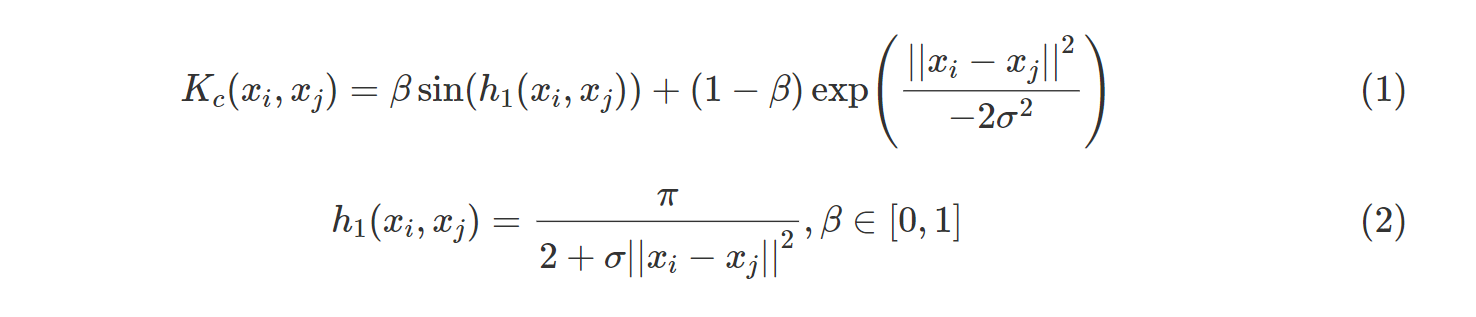
其特色是結合了sin(ℎ1(Xi,Xj))與高斯核,並藉由係數β權衡兩項,生成了一種新的核函數。在論文中作者也以這項核函數Kc、sin(ℎ1(Xi,Xj))與高斯核共三種核函數分別建立SVM模型,對包含Pimalndians1、tic-tac-toe等24種公開資料集進行測試,結果顯示使用Kc的準確率(Accuracy)幾乎都是最高。
在下一章節,我們將以該論文新提出的核函數Kc搭配SVM,實作於常見的公開資料集,比較與高斯核以及多項式核的結果。
實作
資料集
在本章節,我們以UCI Machine Learning Repository的公開資料集「Wine Quality Data Set」來進行實作,這份資料包含了1,599筆不同紅酒樣本的密度、pH值、殘糖等11項特徵,每筆樣本的標籤為其品質分數,從3到8分不等。由於此分數是人為的主觀評價,並非依循固定規則或邏輯,且3、4、7、8分的樣本合計只佔不到18 %,因此在實作時我們將3到5都歸類為低分類別,6到8為高分,高、低分的類別各佔53.5 %與46.5 %。
模型訓練與預測
整份資料隨機分割為80 %作為訓練集以及20 %的測試集,接著以訓練集對SVM的懲罰值C
以及核函數的σ,在2-5到210間進行格點搜尋(Grid search),β與原論文中同樣都設為0.5,訓練與測試集的結果列於表1。
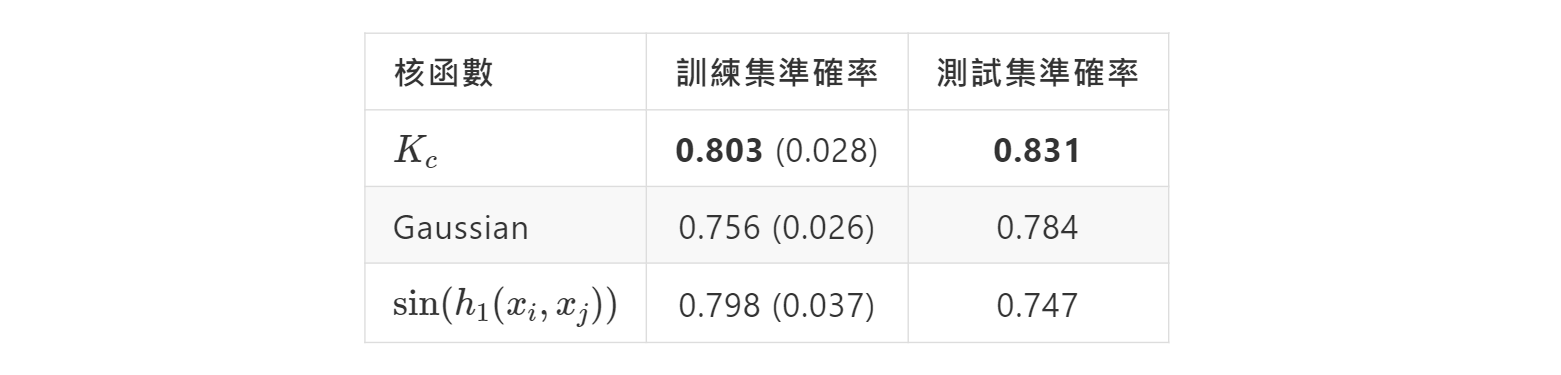
表1:分別使用Kc、高斯與sin核,在訓練集的5-fold交叉驗證準確率(括號內為標準差)以及測試資料準確率。最大值以粗體字標示。
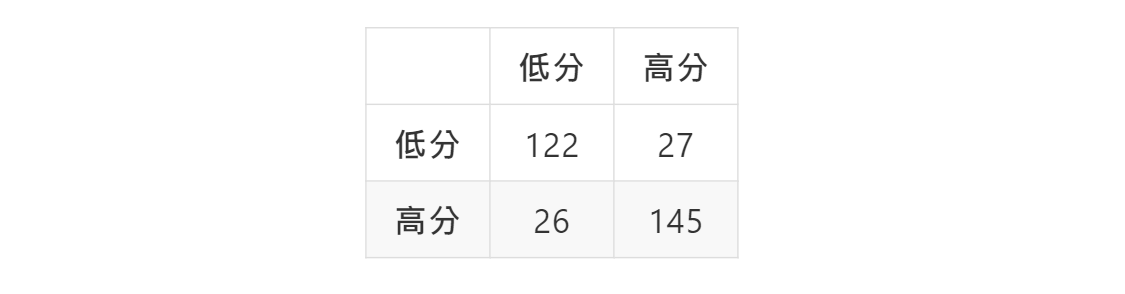
目前為止我們都是固定β=0.5來進行訓練及預測,原始論文的實驗也並未對β進行調整,但我們也好奇若將β也進行調整,會對模型表現帶來什麼影響。因此我們接著將β、C、σ都進行格點搜尋,β的範圍為0.1到0.9,C、σ同樣是2-5到210。結果顯示β=0.4時,相較於預設值的β=0.5,能進一步帶來準確率提升,如表2與圖3,以及表3的混淆矩陣。
表2:不同β值的在訓練集5-fold交叉驗證準確率(括號內為標準差)以及測試資料準確率。最大值以粗體字標示。
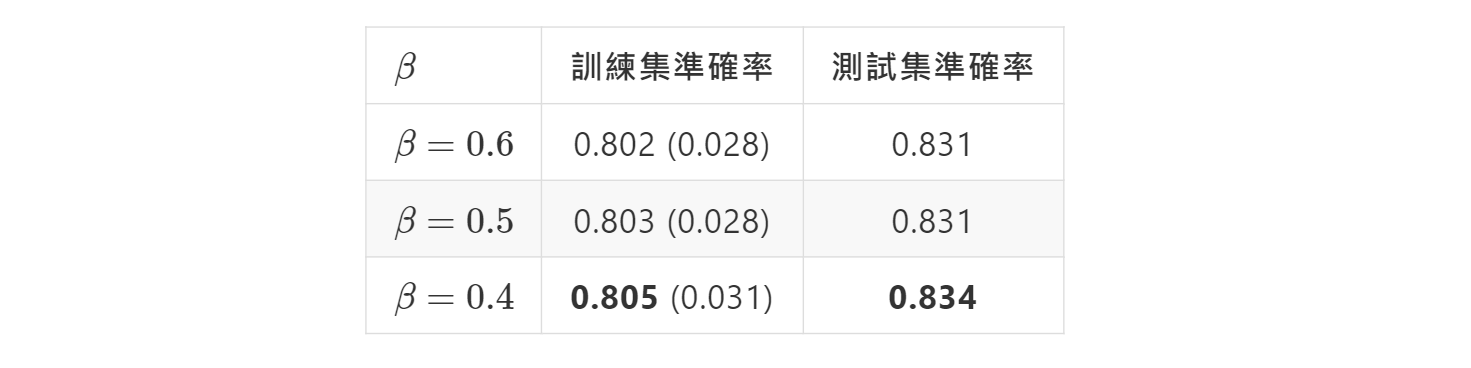
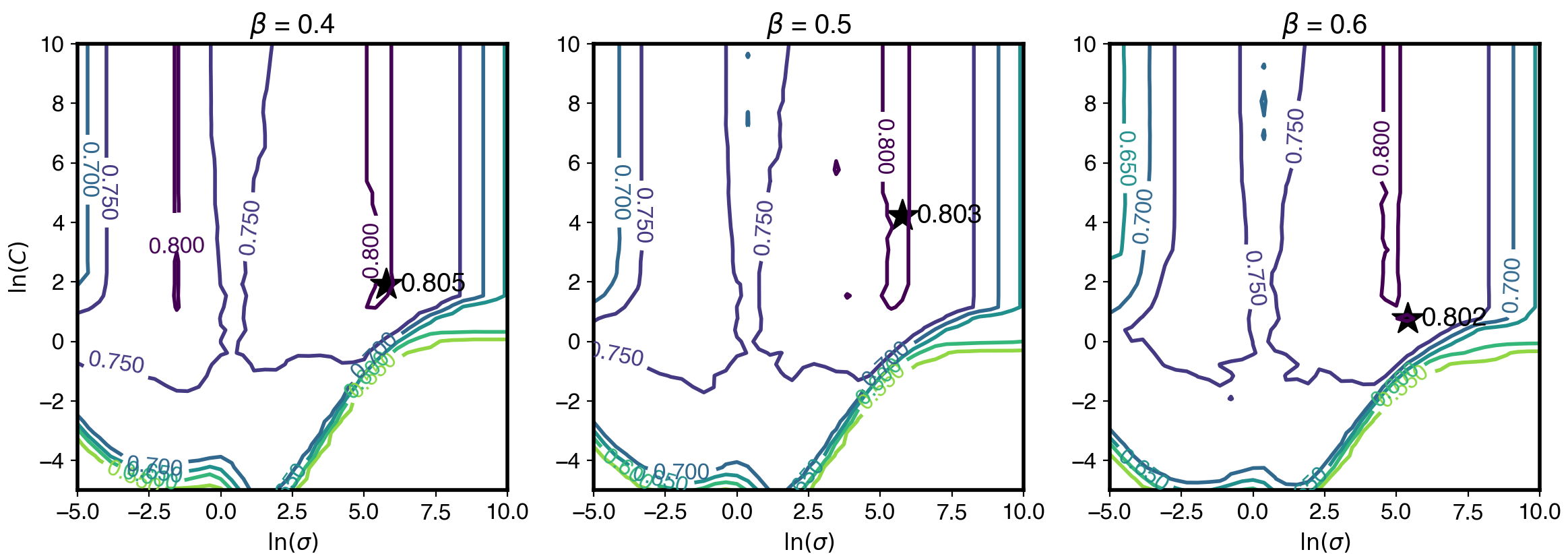
圖3:分別使用β=0.4、β=0.5、β=0.6的訓練資料格點搜尋結果等值線圖。圖中等值線的數值為準確率,顏色愈深者愈高,星號處為最高準確率對應的超參數位置,並在右側標註準確率。
表3:測試集的混淆矩陣。橫列為真實標籤,直行為預測標籤。
實作時,因為scikit-learn尚未支援此核函數,需透過自定義的方式來套用Kc於SVM模型。K_c函數裡的euclidean_distances是用來計算公式裡的歐氏範數(Euclidean norm),其餘的sigma、beta分別對應到式1中的σ、β。
我們在scikit-learn框架下,以sklearn.svm.SVC來建立模型物件,並進行訓練。
由於自定義的核函數已計算SVM的Gram matrix,因此須設定kernel = 'precomputed',讓SVC物件訓練時不再計算Gram matrix,並將原先svm.fit(X, y)的訓練資料X換成K_c(X_train, X_train, sigma, beta)。
除了核函數的定義以及訓練以外,其餘步驟如讀資料、評估指標等,都是一般在sklearn框架下實作的方式。以上未包含針對β進行調整的過程,若要將β也加入格點搜尋,再疊一層迴圈即可;但如果資料集更大或維度更高則建議使用隨機搜尋(Randomized search),以免耗費太多時間把所有超參數組合都嘗試一次。
結論
我們分別以Hafshejani and Moberfard提出的核函數Kc、高斯與sinsin核搭配SVM,使用與原論文相同的β=0.5,實際運用在Wine Quality Data Set上進行訓練與預測,分別得到0.803與0.831的準確率,不論是在訓練與預測集,Kc的準確率都是最高者。而藉由將超參數β也進行格點搜尋來調整,能再提升訓練與測試集準確率達0.805及0.834。
無論是原始論文在24項公開資料集的實驗,或我們的實作,皆顯示Kc在大部分的資料集的準確率,相較於只使用高斯或sinsin核,都能進一步提升準確率,足見其對於SVM的助益。而原論文並未調整的β,我們認為若在實作時加入調整,可再提升模型表現,然而其提升幅度還有待更多資料集的測試。
目前此核函數尚未獲得scikit-learn支援,須以自定義的方式加入SVM模型,但以它對分類結果的提升來看,在訓練SVM模型時仍然值得嘗試。針對不同β值的格點搜尋結果有相似的分佈,我們也認為若難以對三項超參數都進行格點搜尋,採用預設值的β=0.5即可。
參考資料
Boser, B. E., Guyon, I. M., & Vapnik, V. N. (1992, July). A training algorithm for optimal margin classifiers. In Proceedings of the fifth annual workshop on Computational learning theory (pp. 144-152).
Hafshejani, S. F., & Moberfard, Z. (2022). A new trigonometric kernel function for SVM. arXiv preprint arXiv:2210.08585.
(撰稿工程師:吳宇翔)