2019年2月OpenAI發表了GPT-2模型,龐大的架構與優秀的文本生成能力引起了學界的關注。2020年5月,GPT-3強勢來襲,難道AI製造假文章的時代要來了嗎? 本篇文章整理了GPT-3最新的論文概要,並分享訓練GPT-2模型生成中文文本的結果,看看中文的文筆如何?
「使用gpt-2自動產生文章的功能,不過gpt-2的功能不是一個獨立的功能,gpt-2也並沒有直接在內部使用,不過我們也發現gpt-2的功能不太一樣。gpt-2的功能主要是通過自動調節,比如調節文本的速度和轉速,通過調節功能來調節轉矩數,而這些功能的設計都是爲了滿足需求而設計的,比如調節數字轉速的速度,通過轉速計算機來進行計算。這樣的功能很少見,但是在使用gpt-2的時候,可以看得出,gpt-2的功能非常豐富。」
以上段落由GPT-2模型產生,儘管生成了一些似是而非的文字,但可以看出它有掌握到中文的句法概念,前後文也帶有連貫性。
GPT-2的全名為Generative Pre-trained Transformer 2,在2019年2月OpenAI的論文“Language Models are Unsupervised Multitask Learners”提出,使用的是近年來NLP任務非常火紅的Transformer架構。Transformer是採用注意力機制取代循環神經網路的Encoder-Decoder模型,不僅可以處理時間序列還可以平行運算,大大提升了模型訓練的可能性。自從2017年“Attention Is All You Need”這篇論文發表了以後相關的研究便層出不窮,光是將過去使用循環神經網路的模型改用Transformer實現就可以刷一篇論文出來,最近甚至還有用Transformer來做Object Detection的作法。關於Transformer網路上可以學習的資源很多,在Tensorflow官網也有非常詳細的介紹。
回到GPT-2,模型本身是基於Transformer的Decoder ,對layer normalization以及residual layer的初始化稍作修改。訓練使用從800萬個網頁爬來的WebText資料集,容量高達40 GB。模型的參數量也來到驚人的15億之多,要知道,在差不多時間點發表的BERT-Large參數量也「只有」3.4億而已(不得不說,貧窮限制了我的想像)。然而文字的力量太過強大,考慮到濫用模型可能造成潛在問題,也讓OpenAI決定不公開訓練好的模型。

於是便開啟了一波論戰,也引來各路大神的冷嘲熱諷。深度學習三巨頭之一的Yann LeCun首先表態:假設在80年代我們就能預見CNN帶來的負面影響,那我們要不要將CNN保密不公開呢?
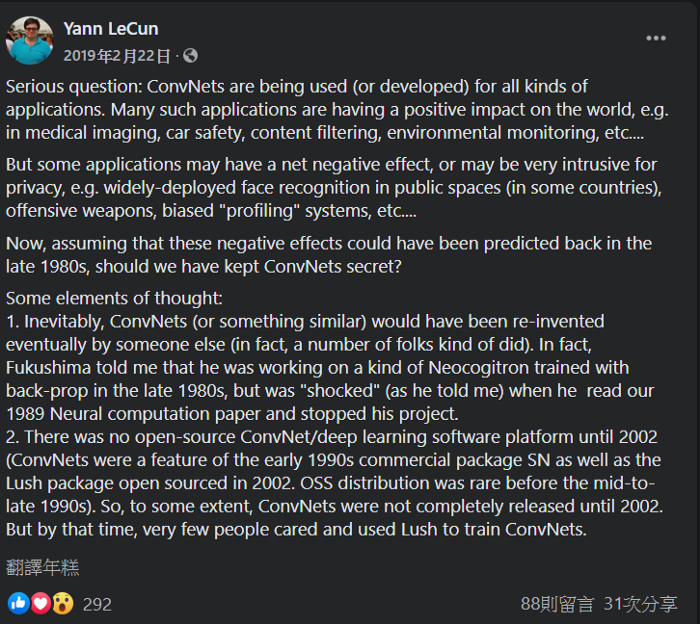
然後他提出了自己的想法,這些模型最終還是會被其他人研究出來,就算公開了模型也未必會一開始就受到關注。
後面他的言論就沒這麼客氣了,例如「拿用MNIST訓練過的CNN辨識郵遞區號可能會被惡意攻擊,大家要小心垃圾郵件恐怖攻擊,趕快買下一座小島去避難吧!」或是「每個人都可能散布謠言或製造假新聞,那我們是不是也該停止生小孩了?」等等。
而模型的效果是否真的這麼強大呢?Keras的作者François Chollet大神表示他花了20分鐘用不基於機器學習的做法就可以達到類似GPT-2 medium的效果。
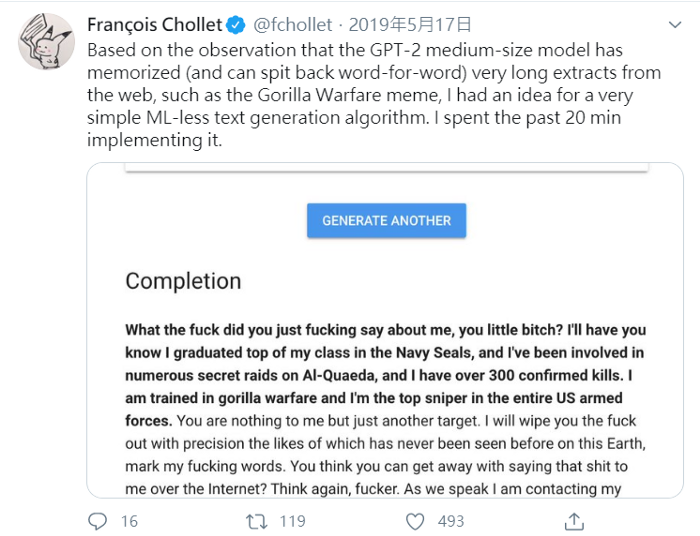
然後狠狠的酸了一波:「我不打算公開程式碼,因為你們沒辦法應付這個腳本蘊含Request,BeautifulSoup和正則表達式的強大力量」
在經過漫長的評估與輿論壓力下,OpenAI陸續發布了GPT-2的模型,在2019年5月發布335M參數的版本,又在2019年8月公開含有 774M 參數的預訓練模型,最後終於在2019年11月釋出最危險的具有15億參數的完整版模型。
現在網路上已有不少的開源項目可以用GPT-2進行中文的文本生成,這裡主要參考了GPT2-Chinese這個項目的實踐,使用250萬篇新聞語料作訓練,資料集大小9 GB,使用的運算設備是4張GTX 1080 Ti。於是總共花了一天的時間…
…做前處理。
這之後每個epoch就要花兩天半左右的時間,跑完5個epoch花了我整整兩個禮拜。來看看GPT-2生成文章的功力如何:
前文:成年偵探,柯南,專門偵辦職場性騷擾案件。這次認定湯姓工程師爲嫌疑犯
GPT-2:成年偵探,柯南,專門偵辦職場性騷擾案件。這次認定湯姓工程師爲嫌疑犯,是因爲湯某在2008年被警方抓捕時,犯罪嫌疑人湯某的身份信息與其經常使用的身份證有異,湯某的身份證也就是一個“小姐姐”的證。據湯某交代,湯某在2008年,曾被一名女工程師發現
前文:你知道他那十六年唸了多少書?他會比你們想像的有料!
GPT-2:你知道他那十六年唸了多少書?他會比你們想像的有料!!!我一直都很羨慕這個世界上那些聰明的人,比如說有人在讀書時會說,他們讀書,會讀的好書!而且這些書對於我的幫助可是巨大的。所以說我希望能夠和大家共同努力,去實現這個目標。我想我會在很久之前的一個夏天,就跟一羣人一起去了,這是我的第一次,也是我第二次。我會在這個夏天,把一切都給了我!我會把這份感情帶到更多人身邊,讓更多人知道我的喜悅!
在隨意實驗的過程也意外地發現,即使模型沒看過遊戲王的文本,也能衍生出卡牌效果的情節:

前文:發動黑魔導女孩的效果,提升雙方墓地裡黑魔導的攻擊力,並且使用次元魔法,特殊召喚一隻魔法師族怪獸,再破壞你的怪獸。由於你的女劍士被破壞了,因此你場上的怪獸攻擊力下降200點
GPT-2:(原文省略)你場上的怪獸攻擊力上升400點。你可以通過增加對方的魔法師族怪獸,來減少對方的攻擊力。這就是黑魔導女孩的魔法效果,讓你的女劍士族怪獸的效果增加200點,你場上的怪獸攻擊力上升500點,你的女劍士族怪獸的效果提升500點。這就是黑魔導女孩的魔法效果,讓你的女劍士族怪獸的效果增加150點,你場上的怪獸攻擊力下降80點。你可以通過增加對方的魔法師族怪獸,來減少對方的魔法師族怪獸。在此過程中,你需要使用次元魔法,增加對方的魔法師族怪獸,這才能讓你的女劍士族怪獸的攻擊力減少500點
實際使用GPT-2的感想是模型雖然龐大可以生成出一些複雜的情境但是並未如OpenAI一開始描述的那麼強大,人物劇情看似連貫但是寫到後面常常會看到人物設定顛倒或者前後矛盾等等情況,有時候有抽樣好幾個句子才找的到比較流暢的案例,或許中文文法的複雜結構也影響了模型的表現。其實OpenAI也有提到他們最大的GPT-2模型也還未over-fit WebText資料集,要完整訓練語言模型並且達到理解自然語言恐怕還有很長的路要走。
2020年5月28日,OpenAI又發表了GPT-3的論文,這次的參數量直接來到1750億!

連作者的數量都是上次的5倍…

這篇論文大概有以下幾個重點:
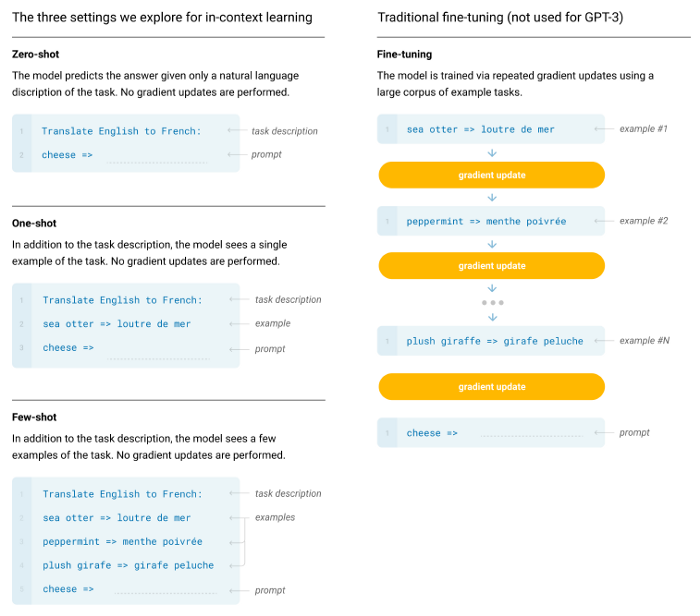
- 專注於少樣本學習任務(Few-shot, One-shot, Zero-shot),驗證提高參數量能提升模型表現。
2. 使用以Common Crawl為主的混合資料集,原始大小在45 TB以上,為了更精確評估模型表現過濾掉一些重複出現在資料集中的數據,資料清理完最後留下約570 GB左右。
3. 模型方面基於GPT-2修改了dense layer並加入類似Sparse Transformer的架構,使用微軟的平台用多張NVIDIA Tesla V100訓練(多張是多少張沒有明確說明,留給讀者一些想像空間^^)
整份論文共73頁,不過只有前10頁是關於實驗方法,後面都是實驗結果分析。就官方說法在特定領域的少樣本學習能達到SOTA的效果,但在某些任務成果有限。訓練好的模型目前也尚未公布,究竟這次會再慢慢擠牙膏將模型釋出,或者因為危險性太高只能讓結果留在實驗室裡?就讓我們拭目以待吧!