每一天,我們都會有開心、難過或是生氣等等不同的情緒反應,大多時候,人類可以透過觀察臉部表情或動作,看出對方的情緒;也可以從語氣或是對話描述聽出說話者的心情。那麼,電腦也可以看出或聽出人類的情緒嗎?
其實,目前在文字與圖像的情緒分析技術都已經有不錯的成果,例如可以利用卷積神經網路 (CNN) 技術提取臉部特徵,並利用這些特徵分辨出圖片中的人物表情是笑或難過。而文字部分的辨識技術也同樣發展得十分成熟,無論是利用RNN或是Transformer模型,都能有效提取出文字序列的相互關係,藉以進行情感分析。

圖像情感分類任務中,好的人臉資訊十分重要
目前情感辨識的做法可分為圖像與文字兩種方式,建議針對想辨識的對象選擇合適的做法,例如想看到的是臉部表情,就該選擇以圖像處理為主的AI技術;如果是分析語意或文字含義,就會使用自然語言處理。
在圖像情感分類任務上,取得一個好的人臉資訊十分重要。因為,如果影像模糊或看不出表情,都很有可能影響模型的決策,也不建議放進模型中進行訓練,以免干擾。
根據圖片量多寡也有不同的模型做法,當圖片量足夠時,建議能建立自己的模型,不僅在模型大小或設計上較有彈性,如果能做出一個只屬於此資料集的模型,在分類上效果也較好。此外,ResNet的skip connection保護措施,也會對自己建立的模型產生出奇不意的效果,建議能搭配使用。
要注意的是,自己建立模型會需要強大的CNN模型背景,也需要考量到資料搜集的難度。
如果圖片量不足時,則可以考慮用網路上公開的人臉預訓練模型進行微調,這麼做的好處是不用自己花時間建模型,要準備的資料量也大幅減少。不過,這樣做的模型較沒有彈性,在應用上,以人臉模型VGGFace為例,如果想要將模型放到較小的嵌入式設備,難度也較高。

大型語言模型的好處
在文字的情感分析中,則需要在資料預處理上花點心思,主要是將輸入的文字轉為能讓模型理解意思的Embedding。
轉換Embedding需要兩個小模組。第一個是Tokenizer,是將一段文字分割成各個小Token,如「I am a boy」會轉換成「I」、「am」、「a」、「boy」,但電腦還是無法理解這些文字,因此,會需要使用BERT等語言模型,將這些Token轉換成Embedding,將這些文字轉成電腦能理解的語言形式。如:「I」變成[1,0,0,0]、「am」變成[0,1,0,0]、「a」轉變成[0,0,1,0]、「boy」則變成[0,0,0,1]。
當文字處理好後,就能拿公開的大型語言模型微調自己的資料集。為什麼要用大型語言模型來微調呢?主要是這些模型在經過大量的資料訓練後,具有強大的語意理解能力,只要稍微調整就能有不錯表現。
當然,也可以選擇自己建立一個NLP Model,但要訓練到具備不錯的成效,所需花費的成本非常驚人,所以大多不會考慮從無訓練到有。

多模態模型將是未來應用趨勢
視覺、聽覺、嗅覺都是一種模態,而多模態就是同時擁有二個以上的模態,當模型能同時接收多個模態的輸入,且做出相對應輸出,就是一個多模態模型,例如日前爆紅的繪圖工具Midjourney。
而多模態的情感辨識該怎麼做?例如輸入人臉表情及文字含義得到一個更準確的情感分類。主要有幾個步驟,首先是作Representation learning,就是將文字及圖像資料,分別丟進自己的特徵萃取器裡,萃取器的目的是讓模型理解人臉臉部的特徵及文字含義。(圖像以CNN為主,文字就以RNN、 GPT為主)而輸出就是一串數字向量,如:一張人臉輸入萃取器後,會輸出[13, 16, 2, 1, 5, 100]的數字陣列,而文字萃取也一樣會輸出一段數字陣列,藉以來表達此段文字。
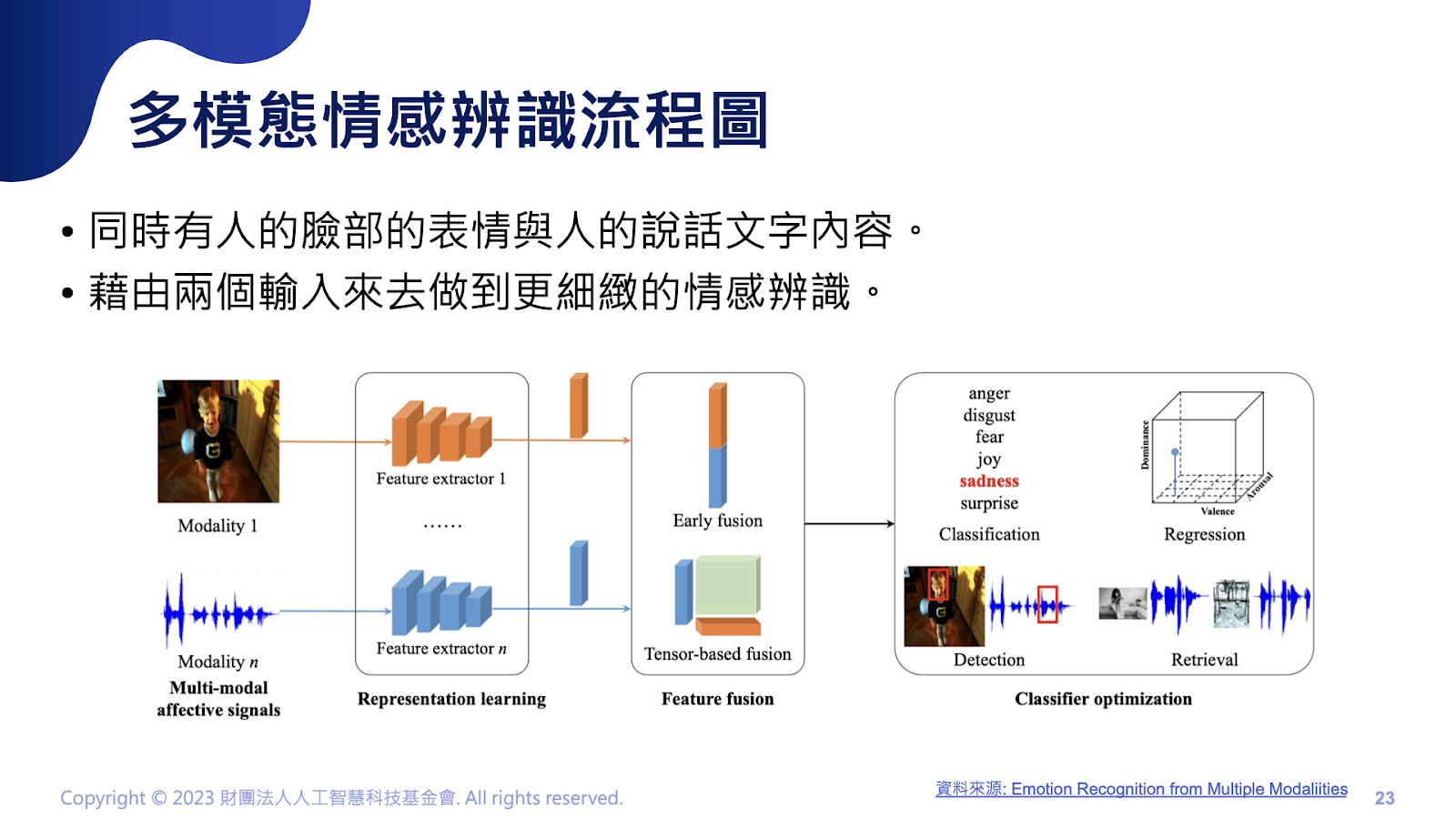
接下來則是Feature fusion,這階段主要整合人臉及文字特徵。主要有兩種做法,分別是Model free以及Model based。Model free就是不使用任何模型,直接合併兩個特徵向量。優點是效率高且沒有其他運算成本,但缺點就是得不到這兩者特徵的上下文關係,很難對應兩者資訊,也可能導致後面的分類器沒辦法有效抓出兩者的pattern。
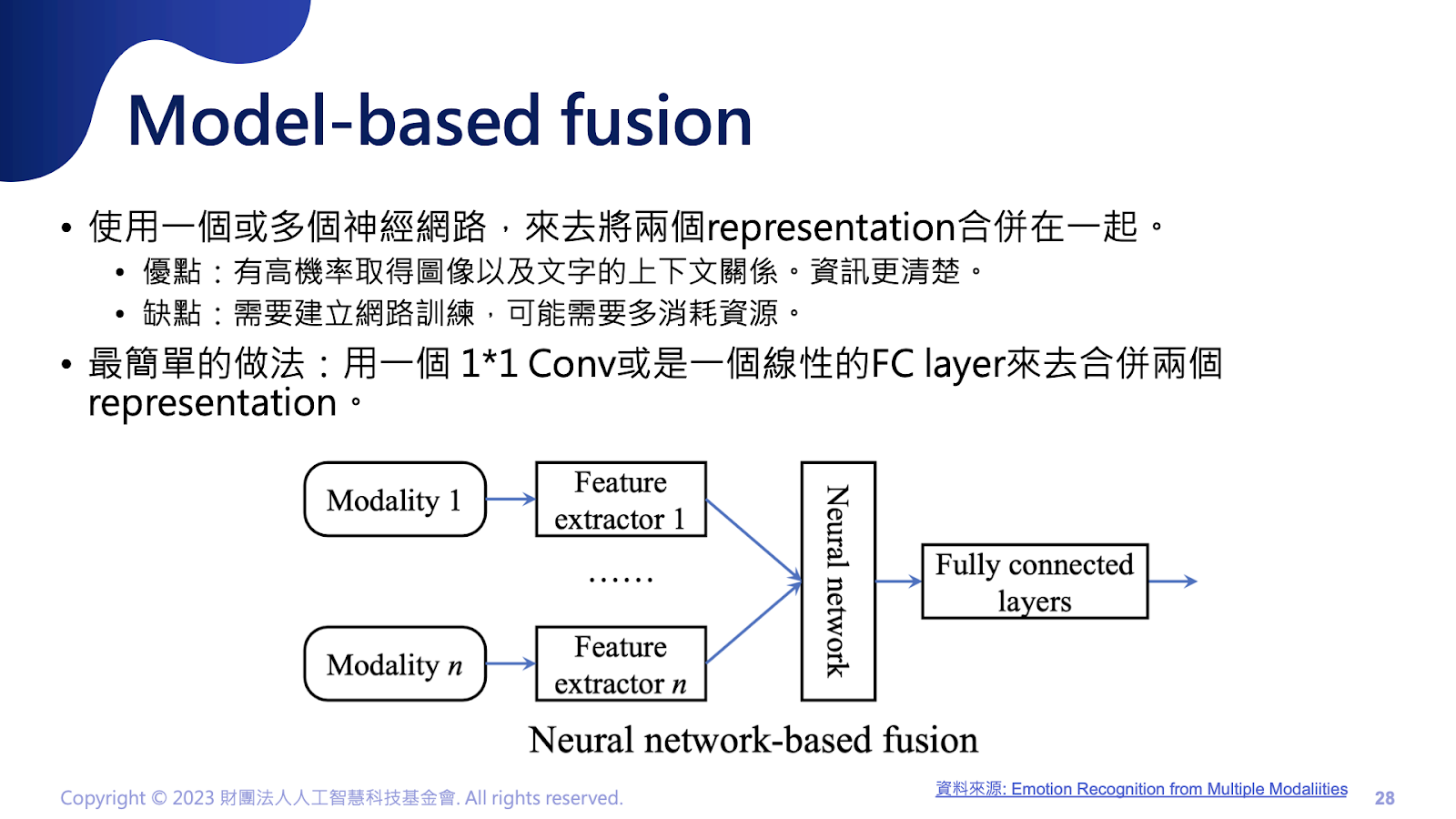
而Model based的方法,也是目前常見的方法,就是用一個簡單的類神經網路學習這兩者的特徵pattern,目前常見的做法是用一個簡單1 x 1 卷積,學習兩者之間的representation。但是,這個做法將耗費額外的運算成本。
不管是影像或文字,甚至是上述的多模態模型整合,都已具有不錯的效果,開發者可以用自己的資料或目標輸出,作為做法選擇上的判斷依據。而越來越熱門的多模態模型,也會在情感辨識上有更多使用與應用。
想了解更多文字與圖像的情緒技術,請參考【AI CAFÉ 線上聽】小心被AI「暗算」,情感辨識大解析!