賭場熱門的輪盤遊戲也可以用到人工智慧技術?這篇文章中除了介紹輪盤遊戲的玩法與強化學習概念,並且藉此評估三種不同的投注策略,文章中還分享了如何建置一個用來訓練強化學習的輪盤環境。
輪盤遊戲(Roulette)是一種起源於法國的賭場遊戲,Roue在法文裡就是輪子的意思,在遊戲中玩家可以投注單個數字、顏色、或是一段數字區間。
這篇文章將使用強化學習來評估三種不同的輪盤投注策略,評量的指標包含勝率與總收益。首先我會介紹輪盤遊戲的玩法與強化學習的基本概念,然後我會說明如何建置用來訓練強化學習的輪盤環境,接下來講解演算法與實驗方法,文章的最後則是實驗結果與進一步的探討。
使用的程式碼可以在GitHub找到。
輪盤遊戲怎麼玩?
在每一輪的遊戲中,你需要決定下多少賭注,然後選擇檯面上的選項下注。輪盤桌的布局如下所示:

各類投注方式與賠率可點此了解:
在這個項目中我預設玩的是歐式輪盤,與美式輪盤的差別在於美式輪盤多了「00」的格子,所以歐式輪盤中會有0到36,共37個格子;而美式輪盤則是38個。
經過一小段時間後莊家會滾動輪盤與球,之後便停止下注。為了建置輪盤遊戲的環境,我們需要了解莊家操作輪盤的一系列手法,建議對輪盤遊戲不熟悉,卻又想進一步了解的朋友,可以先在影音網站上搜尋相關的影片。
輪盤最終停止轉動,而球會落在其中一個格子裡,之後莊家會對預測正確的玩家,發放相對應的籌碼。
你必須先知道的重要知識:強化學習
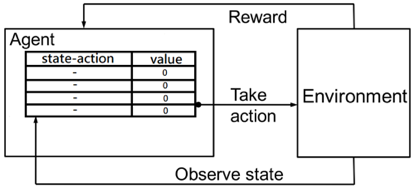
強化學習是機器學習的一個分支,我們要訓練一個代理人 (Agent) 與環境(Environment)互動,代理人觀察當前的狀態 (State) 採取行動 (Action),Environment根據Agent採取的行動更新狀態並給予獎勵 (Reward),最終目標是能讓獲得的獎勵最大化。
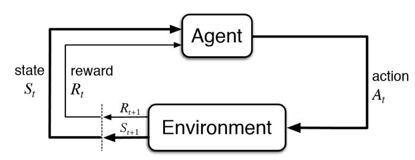
與監督式學習不同的是,我們不能即時反饋給Agent每個行動是好或壞。舉例來說,在玩井字遊戲時,訓練初期,Agent只能隨機探索,所以他可能會將第一步下到九宮格裡邊邊角角的位置。這通常是很糟糕的下法,但由於遊戲還沒結束,所以我們也沒辦法讓Agent知道結果。這時,我們可以採取的作法是,讓遊戲進行到結束,再將獎勵一步一步往前回饋到先前的狀態。經過一段時間訓練後,Agent就能依據過去的經驗選擇最佳的行動,所以在選擇第一步時它應該就會下在中間的位置,因為這樣的下法勝率最高。
建立輪盤遊戲環境
為了在輪盤遊戲使用強化學習我們需要定義好兩個重要元件:Agent和Environment。Agent根據我們使用的演算法選擇Action,也就是選擇要投注的目標,Environment則是當莊家將輪盤結果與獎金反饋給Agent。理想情況的Environment是能直接使用實際賭場的遊戲數據,然而由於沒有這方面的公開資料集,我們得自己生成實驗數據。幸運的是,這個遊戲已經有一套定義好的獎勵機制了,所以我們只要想辦法模擬莊家操作輪盤的手法就好。
網路上已有一些用Python來玩輪盤遊戲的開源項目,然而在模擬輪盤轉動時,你最有可能看到的是下面這行代碼:
random.randint(0, 37)
但這是不入流的做法,輪盤是一個更加複雜的遊戲。
模擬輪盤的轉動需要考量以下六個因素:
- 莊家要在先前落下的位置將球拿出來,轉動輪盤給予一個方向的加速度,然後讓球沿著反方向轉動。
- 第一步的轉動會交替使用順時針與逆時針方向。
- 莊家的轉動力道。
- 球與格子的物理碰撞。
- 輪盤的傾斜角度。
- 人為操作的誤差,包含莊家換人操作,或莊家忘記轉換方向等等,都可能會造成不同的資料分布。
我從網路上找了輪盤的開源項目並修改了輪盤的轉動方法。前三項因素可以透過在程式裡設定方向與合理的隨機力道(轉動輪盤與球)來完成,第五項和第六項在莊家是機台的情況下是可以忽略的(所以我也這麼做了),第四項較為複雜目前先留在以後的改進計畫。
設定好環境以後我跑了十萬筆的遊戲紀錄。我將前面9萬次當作訓練集,後面1萬次當作測試集,下面是拿訓練集與測試集的顏色與數字出現次數畫出的長條圖。
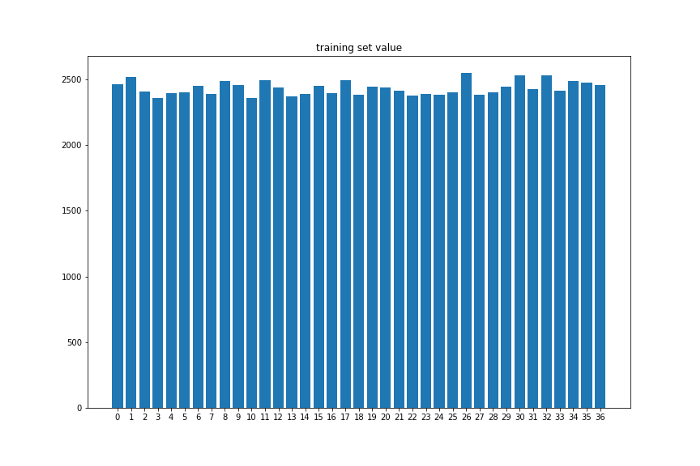
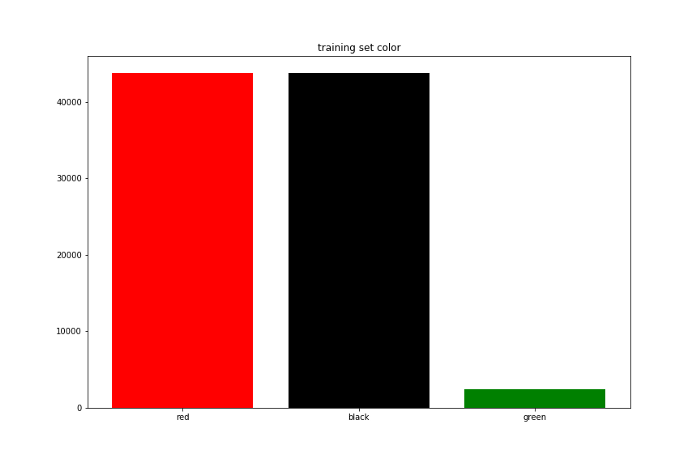
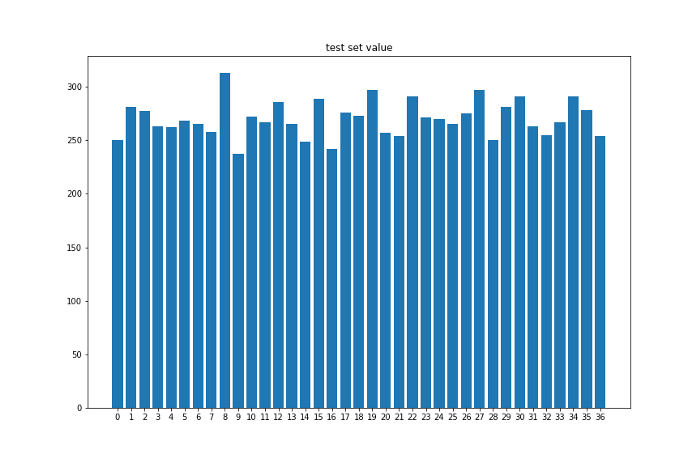
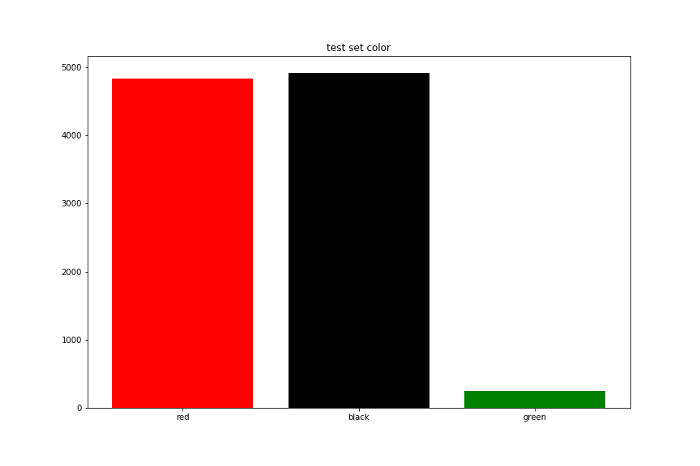
可以看到在設定完一些限制與加入隨機性後資料集還是呈現均勻分布,接下來就來看看RL agent是否能在這樣的模擬環境裡贏錢。
演算法與實驗方法
為了衡量不同策略的表現,我將遊戲紀錄分為好幾個回合,每回合會有100筆紀錄,前面20筆只做為觀察使用,Agent從第21筆紀錄開始玩。總共會有900個訓練回合與100個測試回合。取20筆觀察值的原因是賭場機台預設就讓你回看過去20筆紀錄。
強化學習的其中一個經典算法是Q-learning,其中的「Q」代表quality的意思。Q-learning的核心概念是評估在當前的狀態可採取的品質。我們會用一張q-table來儲存當前的狀態s採取行動a的q-value。q-value的初始值是0,然後隨著訓練過程我們採取一連串行動得到獎勵r,可以透過Bellman Equation來更新q-value。
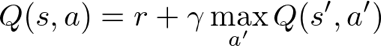
看起來很合理,那我們可以拿來玩輪盤了嗎?
事實上,還有一個小問題需要解決…
記得我們將前20筆紀錄做為觀察值嗎?在歐式輪盤中轉盤一共有37個格子,所以我們能觀察到的狀態一共有37²⁰種可能性。
所以問題在哪裏呢?通常我們會用fp32的精度來儲存q-value,當存在37²⁰種狀態時,q-table的大小趨近於可執行的行動數乘以10³² 個Bytes,這基本上超過世界上任何一個資料中心的容量,更不用說我們還需要相應的資料量來訓練q-table。
這時深度學習就能派上用場了,我們可以用深度神經網路來取代q-table,這就是Deep Q-learning的概念。(詳細資料請參考這裡)
將預測的最大值做為要採取的行動,使用損失函數與反向傳播來更新網路的權重。
回到實驗的部分,我選擇以下三種投注策略做比較:
- Straight up: 下注單個數字(包括0)
- 1 to 1 combinations: 賠率是1賠1的選項組合(奇數、偶數、紅色、黑色、1到18、19到36)
- 2 to 1 combinations: 賠率是1賠2的選項組合(第一欄、第二欄、第三欄、1到12、13到24、25到36)
Agent從當前策略中選擇一個選項下注。另外也有可以pass的選項,因為我更希望Agent能夠學會在某些時候只做觀察並等待更好的時機下注。
在每回合Agent會得到1000元本金,下一注要投50元。當本金輸光或贏超過2000元則算這回合結束。玩滿80次時回合也會結束。這個實驗會比較分別使用三種策略的Agent的總獲利、勝率、以及達到終止條件所需次數。
實驗結果與討論
下面是三種Agent遊玩100個測試回合的結果:



可以試著猜猜看,三種結果對應到哪一種策略。Agent one的勝率最高,總共贏了47450元,在大多數情況下,它都要花80步達到終止條件。Agent two不管看到什麼情況,都選擇pass,100個回合都是沒輸沒贏,也因此都要等到80步回合結束。Agent three贏了最多錢且還有百分之六十二得勝率,而它的回合通常也會提前結束。
原來Agent one使用的是2 to 1 combinations而Agent two是基於1 to 1 combinations,這表示Agent three用的是Straight up策略,這個策略贏了本金122.7倍的錢!
對此,我的看法是1 to 1 combinations的獎勵較少,相對也更難優化網路,所以在前期的訓練經過一些挫折後,Agent便決定放棄了。2 to 1 combinations是對步步為營的人來說,較好的策略。但如果你的目標是贏大錢,你可以選擇Straight up策略。
我們已來到這篇文章的尾聲,這次的分享介紹了輪盤遊戲的玩法與強化學習,並提供了一個結合這兩者的案例,透過Deep Q-learning回測輪盤投注策略。強化學習還有更多值得研究的內容,希望經過以上內容能引發您的興趣。
關於此項目的後續工作,目標是改進Agent能支援一次下多注與調整賭金,另外還有加入物理碰撞,創造更加真實的環境。若您有任何建議或有相關數據可以提供,以做為學術研究也歡迎與作者聯繫。
希望您喜歡這篇文章並願意嘗試在您自己的應用使用強化學習,感謝您的閱讀!
本文作者為人工智慧科技基金會工程師吳品曄,點這看更多個人精彩文章
本篇原文《An income back test of three roulette strategies based on Reinforcement Learning》